
在終於訓練出一個表現十分良好,又符合商業目標的模型之後,接下來就要將模型部署上線啦!這是一個關鍵環節,讓你的模型不只停留在個人電腦中,也可以鑲嵌在產品中,為提供消費者這項功能。
模型部署需要考慮到許多實際問題,開發者通常會面臨兩類主要挑戰:
在實際上線的產品環境中,模型的表現可能會因為資料漂移(data drift)和概念漂移(concept drift)而受影響,不一定會像在訓練階段那樣理想。
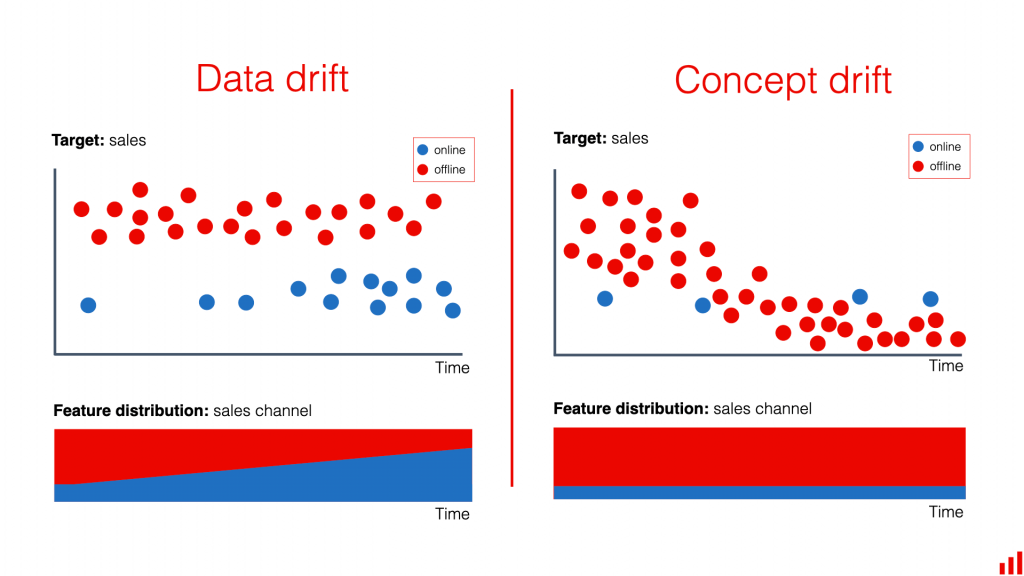
圖片來源:https://www.evidentlyai.com/ml-in-production/data-drift
定義:資料漂移指的是模型的輸入特徵可能會隨著時間而變化,這種變化可能導致模型性能下降,因為模型是基於舊的資料分佈進行訓練的。如上圖所示,online 和 offline channel 的比率發生變化,代表模型輸入特徵的分布改變了。
舉例
檢測和處理:為了避免這個狀況,我們需要定期監控輸入數據的統計特性,或是定期重新訓練模型以適應新的數據分佈。
定義:概念漂移指的是輸入特徵(X)與目標類別(Y)之間的映射關係發生變化,這種變化可能導致模型的預測規則不再有效,即使輸入數據的分佈保持不變。如上圖所示,儘管 online 和 offline channel 的比率不變,但是 offline channel 的平均銷售量隨著時間而下降。
舉例
檢測和處理:為了處理這個問題,我們需要持續監控模型性能,也可以使用滑動窗口(sliding window)或加權樣本來強調最近數據。另外,也需要定期重新評估和更新特徵工程。
如何將模型整合到實際系統中並保持穩定運行是另一個挑戰,需要解決系統架構和運營問題,例如運算資源的分配、性能要求和營運監控等。
在部署模型時,需要仔細考量以下幾點:
在部署模型時,通常不會直接將新模型取代舊有模型,而是需要一段觀察測試期,或是同時運行兩個版本,方便切換。以下是幾個常見的部署方式:
影子模式(Shadow Mode)
在這種模式下,系統並不使用新模型的預測結果,而是觀察其表現,讓人類對模型的預測進行檢驗和評估。
金絲雀部署(Canary Deployment)
當準備好切換至新系統時,先將一小部分流量(如 5%)導入新系統,並持續監控其表現,隨著系統的穩定性增加,逐步提升流量。
藍綠部署(Blue/Green Deployment)
Blue 代表舊版本,Green 代表新版本。這種方式允許兩個版本同時運行,並且可以在需要時立即切換至新版本,而當出現問題時,能夠快速退回至舊版本。
經過今天的內容後,我們終於將模型部署上線,呈現在用戶面前啦!但是,別以為你的工作就此結束哦,我們還是要持續觀察模型跟資料的狀況,才是一個負責任的好資料科學家!明天讓我們來看看要如何持續監控系統的表現吧!
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
如果有任何問題想跟我聊聊,或是想看我分享的其他內容,也歡迎到我的 Instagram(@data.scientist.min) 逛逛!
我們明天見!
